The video on the left was generated by CogVideoX-2B (100 NFE). In the same amount of time, TDM (4NFE) can generate 25 videos, as shown on the right, achieving an impressive 25 times speedup without performance degradation.
Abstract
Accelerating diffusion model sampling is crucial for efficient AIGC deployment.
While diffusion distillation methods---based on distribution matching and trajectory matching --- reduce sampling to as few as one step, they fall short on complex tasks like text-to-image generation.
Few-step generation offers a better balance between speed and quality, but existing approaches face a persistent trade-off: distribution matching lacks flexibility for multi-step sampling, while trajectory matching often yields suboptimal image quality.
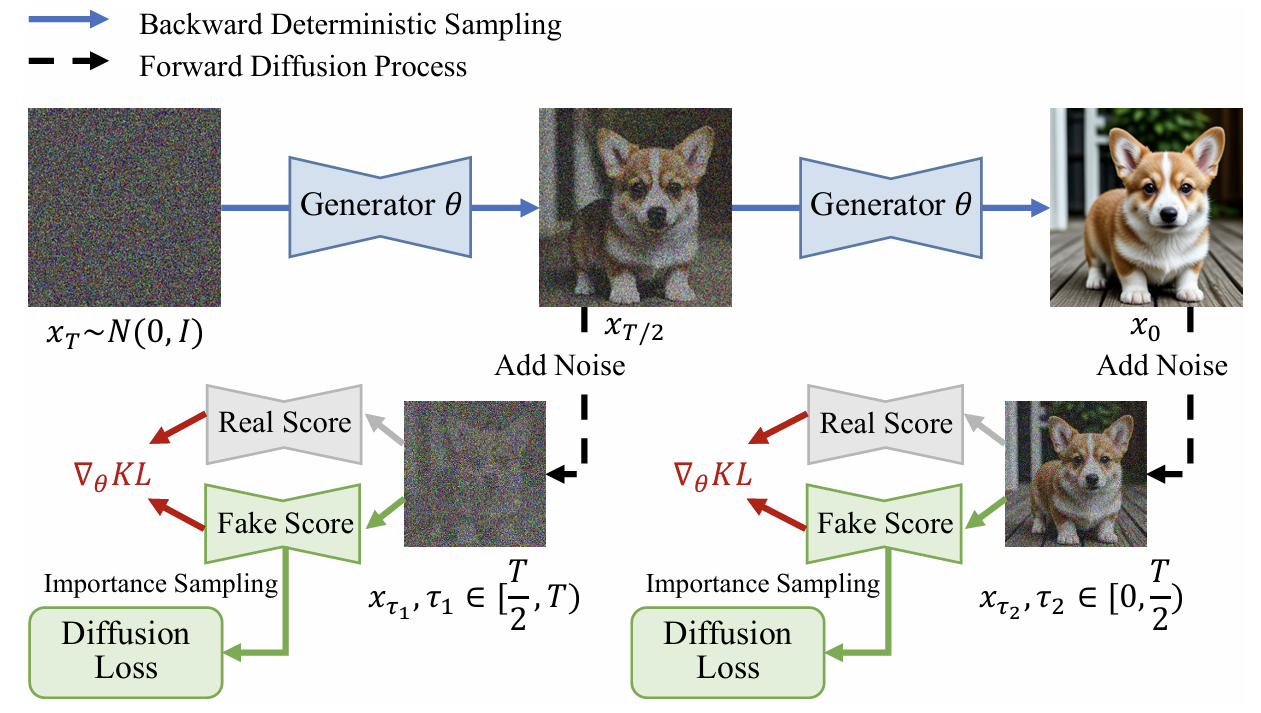
To bridge this gap, we propose learning few-step diffusion models by Trajectory Distribution Matching (TDM), a novel framework that combines the strengths of distribution and trajectory matching.
Our method introduces a data-free score distillation objective, aligning the student's trajectory with the teacher's at the distribution level.
Further, we develop a sampling-steps-aware objective that decouples learning targets across different steps, enabling more adjustable sampling.
This approach supports both deterministic sampling for superior image quality and flexible multi-step adaptation, achieving state-of-the-art performance with remarkable efficiency.
Our model, TDM, outperforms existing methods on various backbones, such as SDXL and PixArt-\(\alpha\), delivering superior quality and significantly reduced training costs.
In particular, our method distills PixArt-\(\alpha\) into a 4-step generator that outperforms its teacher on real user preference at 1024 resolution. This is accomplished with 500 iterations and 2 A800 hours---a mere 0.01% of the teacher's training cost.
In addition, our proposed TDM can be extended to accelerate text-to-video diffusion.
Notably, TDM can outperform its teacher model (CogVideoX-2B) by using only 4 NFE on VBench, improving the total score from 80.91 to 81.65.
Video Gallery
Tacher Samples (CogVideoX-2B 100 NFE).
TDM Samples (4NFE).
Tacher Samples (CogVideoX-2B 100 NFE).
TDM Samples (4NFE).
Tacher Samples (CogVideoX-2B 100 NFE).
TDM Samples (4NFE).
Tacher Samples (CogVideoX-2B 100 NFE).
TDM Samples (4NFE).
Tacher Samples (CogVideoX-2B 100 NFE).
TDM Samples (4NFE).
TDM can generate high-quality videos in 4 NFE, without performance degradation compared to its teacher video diffusion.
User Study Time!
Which one do you think is better? Some images are generated by Pixart-\(\alpha\) (50 NFE). Some images are generated by TDM (4 NFE), distilling from Pixart-\(\alpha\) in a data-free way with merely 500 training iterations and 2 A800 hours. All images are generated from the same initial noise.
Click for answer
Answers of TDM's position (left to right): bottom, bottom, top, bottom, top.
Methodology
Our TDM builds non-trival connection between trajectory distillation and distribution matching, deilivering a new distillation paradigm: Trajectory Distribution Matching.
TDM combines the strengths of distribution and trajectory matching. Our method introduces a data-free score distillation objective, aligning the student's trajectory with the teacher's at the distribution level: preserving the trajecotry knowledge and avoid difficult instance-level matching.
Benefiting from the proposed design, our method possesses the following advantages:
1) Supporting various ODE samplers for both training and inference,
2) Ultra fast training,
3) Extremely high-quality few-step generation: TDM can surpass the teacher without extra high-quality data in real user preference!
Qualitative Comparison
We present the qualitative comparison to existing SOTA methods below.
It is clear that our method has better visual quality and text-image alignment compared to competing baselines and even the teacher diffusion with 25 steps.
Real User Preference
To further verify the effectiveness of our proposed method, we conduct an extensive user study across different backbones.
The results are shown in below: Our method clearly outperforms the teacher diffusion and other most competing methods in a image-free way.
Text-to-Video Acceleration
Our TDM can be extended to text-to-video acceleration, benefiting from its quick convergence and data-free property.
We distill our 4-step TDM from CogVideoX-2B. We evaluate our method on the widely used VBench. Results in below show that TDM surpasses the teacher CogVideoX-2B by a notable margin while being around 25 times faster.
BibTeX
@misc{luo2025tdm,
title={Learning Few-Step Diffusion Models by Trajectory Distribution Matching},
author={Yihong Luo and Tianyang Hu and Jiacheng Sun and Yujun Cai and Jing Tang},
year={2025},
eprint={2503.06674},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Project page template is borrowed from DreamBooth.
 Which one do you think is better? Some images are generated by Pixart-\(\alpha\) (50 NFE). Some images are generated by TDM (4 NFE), distilling from Pixart-\(\alpha\) in a data-free way with merely 500 training iterations and 2 A800 hours. All images are generated from the same initial noise.
Which one do you think is better? Some images are generated by Pixart-\(\alpha\) (50 NFE). Some images are generated by TDM (4 NFE), distilling from Pixart-\(\alpha\) in a data-free way with merely 500 training iterations and 2 A800 hours. All images are generated from the same initial noise.